
В останній день акції Shipmas, в рамках якої було обіцяно протягом 12 днів показувати, анонсувати та розповідати про нові ШІ-функції, компанія OpenAI представила кілька великих мовних моделей нового покоління o3 та o3-mini, які мають здатність розмірковувати.
OpenAI зазначає, що не йдеться про випуск нових мовних моделей сьогодні. Компанія пояснила, що навчання цих нейромереж ще не завершено і остаточний результат навчання може відрізнятися від того, про що вона говорить сьогодні. У той же час OpenAI приймає заявки дослідницької спільноти на тестування цих моделей перед їх публічним випуском. Компанія ще не вирішила, коли це станеться.
У вересні цього року OpenAI запустила ШІ-модель, яка «розмірковує» o1 (кодова назва Strawberry). Рішення назвати нові моделі o3 пов’язане з тим, що таким чином компанія вирішила уникнути плутанини (або конфліктів товарних знаків) із британською телекомунікаційною компанією O2.
Термін «розмірковуюча модель ШІ» останнім часом став дуже модним у середовищі розробки технологій штучного інтелекту та машинного навчання. Однак, по суті, він означає лише те, що для вирішення цього питання машина розбиває задані інструкції на дрібніші завдання. Це зрештою дозволяє досягти від неї більш точного результату. «Розмірковуюча» модель ШІ найчастіше показують весь процес рішення і те, як ШІ прийшов до тієї чи іншої відповіді, а не просто дають остаточну відповідь без пояснення.
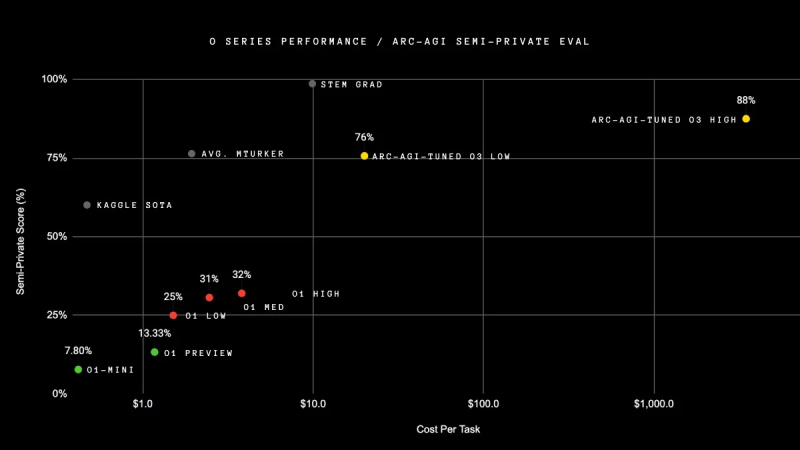
Як стверджує OpenAI, її нова модель o3 перевершує попередні рекорди продуктивності в усіх напрямках. В рамках тесту ARC-AGI, який був спеціально створений для порівняння можливостей штучного інтелекту з інтелектом людини, модель o3 більш ніж утричі перевершила можливості o1, продемонструвавши результат у 88%.
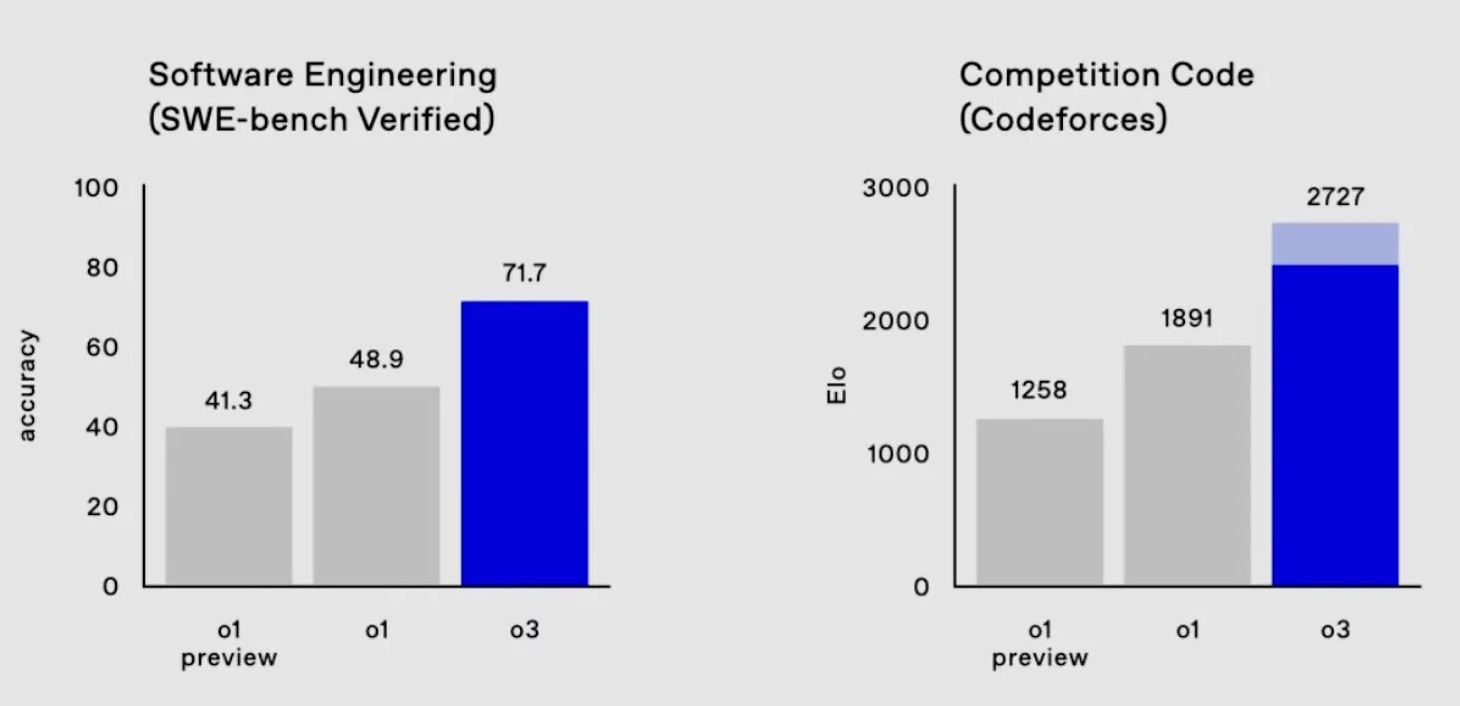
Нова модель також швидше за попередника в написанні коду (тест SWE-Bench Verified) на 22,8% і навіть перевершила провідного вченого OpenAI у спортивному програмуванні.
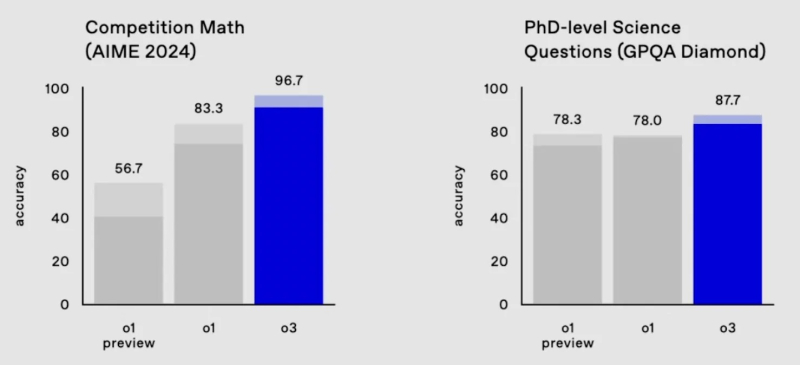
Модель o3 майже впоралася з одним із найскладніших математичних тестів, AIME 2024, пропустивши в ньому лише одне питання, а також набрала в бенчмарку GPQA Diamond 87,7% – значно більше ніж будь-який результат людини-експерта.
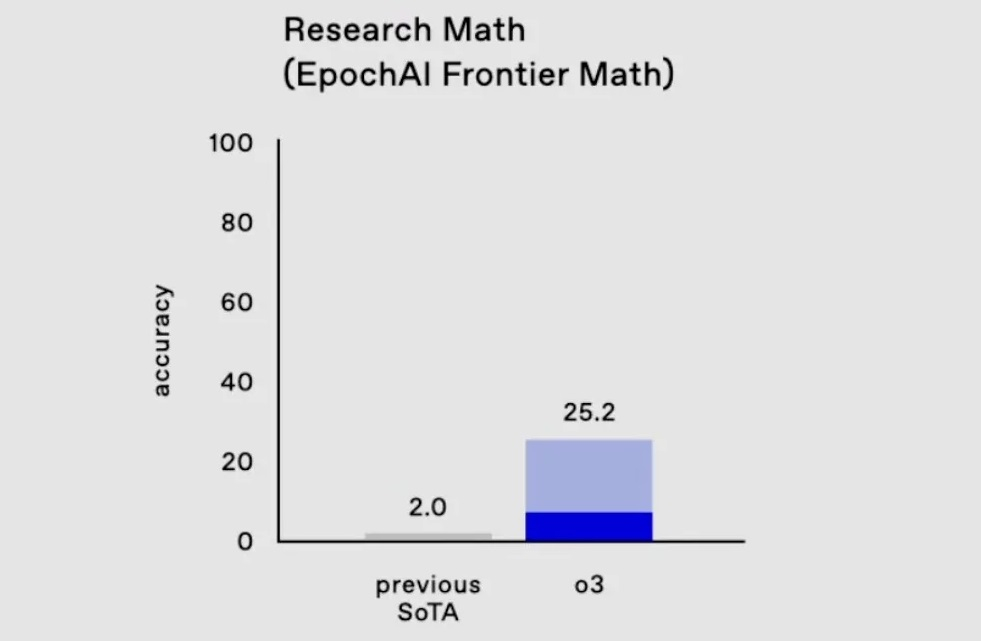
У найскладніших математичних та логічних тестах, які зазвичай ставлять у глухий кут будь-які інші ШІ, o3 вирішила 25,2 відсотка завдань — результати інших моделей не перевищують і двох відсотків.
Вагомою перевагою o3, як і o1, є можливість моделей «міркувати» та ефективно перевіряти свої ж факти, щоб уникати різноманітних помилок і галюцинацій. Щоправда, розробники з OpenAI заявили, що процес перевірки фактів перед видачею відповіді призводить до невеликої затримки – від кількох секунд до кількох хвилин (залежить від складності питання). Крім того, затримка пов’язана з тим, що модель визначає, чи відповідає запит користувача щодо політики безпеки OpenAI. Компанія стверджує, що при тестуванні нового алгоритму захисту на o1 вона набагато краще дотримувалася правил безпеки, ніж попередні моделі, включаючи GPT-4.
І все ж, як зазначають журналісти TechCrunch, основним недоліком моделей, що «розмірковують», є те, що для їх роботи потрібно набагато більше обчислювальних потужностей, тому в результаті їх використання обходиться значно дорожче за «звичайні» рішення.
{kind=link}